
In the past, the traditional data storage mechanisms were often cleanly divided between file storage, NoSQL and relational transactions, and data warehouses. The data warehouse was often a monolithic system, servicing the needs of both customers and internal stakeholders. With the explosion of data, the days of the single-system approaches have come to an end. For the modern data practitioner, it’s critical to consider the advantages of a cloud-hosted environment to dynamically support the growing data storage needs. As a result, you often find yourself having to rely on the strengths of multiple different components rather than any one single system. Over time, patterns have emerged which optimize this approach and ensure it remains manageable. The dominant approach is the Modern Data Warehouse (MDW).
If you’re just getting started with MDW, it’s very easy to fall into the trap of thinking of this as a set of specific technologies that must be adopted. This is the first in a series of posts is designed to help you understand the reasons behind the design pattern to improve your ability to adopt this approach.
Microsoft’s Azure Architecture site documents the MDW Architecture and includes the following diagram:
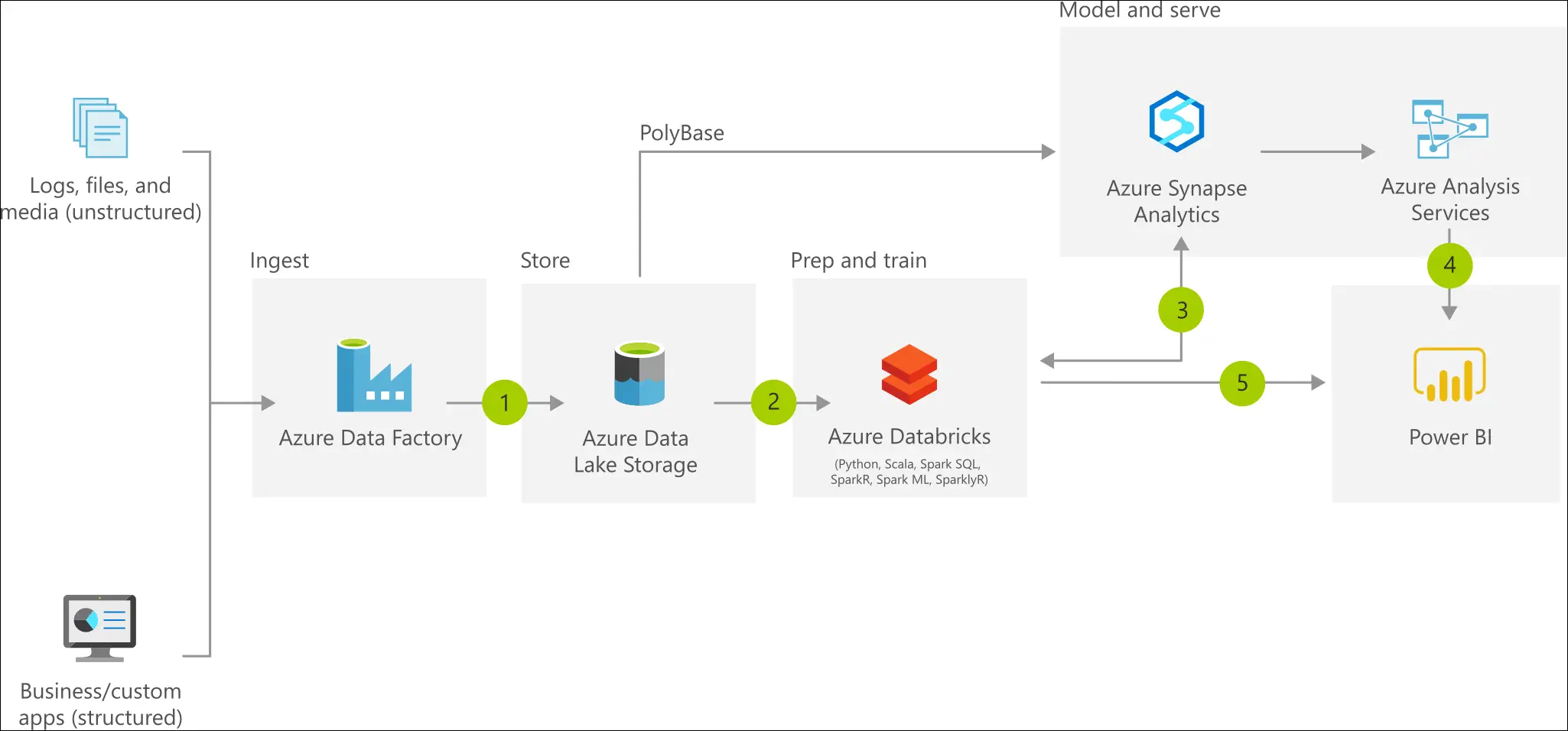
On the surface, it seems that Microsoft is advising specific technologies should always be used to implement this pattern on Azure. The truth is that this is really just showing one of several methodologies, highlighting the diversity of tools available to support this pattern. Each tool supports a specific part of a larger process, and each must be understood in the context of that process. Blindly adopting the tools without understanding the reasons behind them is a recipe for a very expensive disaster!
Diving deeper, the MDW architecture is a combination of multiple aspects, including:
- Reporting
- Business intelligence (BI) and data analytics
- Data modeling and transformation
- Data cataloging and management
- Data quality services
- Relational, non-relational, and streaming data processing
There is no single solution that provides complete support for all of these workloads. Instead, we see a move towards using multiple, distributed systems together to accomplish these goals. To maximize the value of this system, we need to employ the right tool for the job at the right stage of our process.
At a high level, we can break the data process into four steps: ingest, prepare, model, and serve. These aspects are not unique to a MDW. In fact, they are standard data science practices.

Every step implies and interaction with data storage, and the process of bringing these together requires some form of orchestration. Throughout the process, the data must be evaluated and the quality ensured. It’s important to understand that this pattern DOES NOT replace the traditional data warehouse or dimensional modeling. Instead, it provides a proven approach for enjoying the benefits of these approaches at cloud scale.
In the next article, I’ll start to dissect these components and the reasons behind some of the technology choices.