
Data ingestion is the first step in the journey of creating a modern data warehouse. Essentially, this is the process of transporting data from one or more sources to storage, allowing it to be accessed and analyzed. The ingestion process is sometimes split into these two aspects, the service responsible for receiving the content and the storage solution. We’ll explore both aspects in this series.
Ingestion is the foundation of data processing and analytics. Although often the least discussed, it is often the component most directly responsible for determining the performance and cost of the overall system. The reason for this is tied to the fact that dealing with big data is a trade off between compute, storage, and latency. These tradeoffs require careful balancing, selecting the tool or technology that is optimized for the problem being solved.
To optimize the compute load during ingestion, the data should be able to be processed before the next set of data arrives. A system that can process the data in this manner is said to be stable. This maximizes the utilization of the compute resources. By comparison, an unstable system is one in which the processing time exceeds the interval between data sets. In this case, the compute resources are both receiving one batch and processing another. While occasional instability is acceptable, a system that continuously experiences instability and delays will eventually consume all available resources or delay processing to the point of failure.
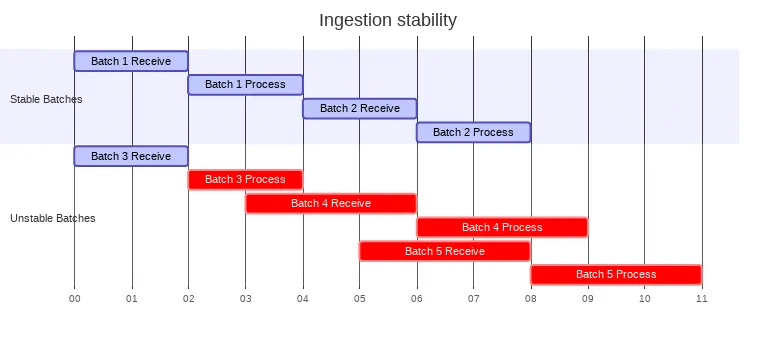
There are two two methodologies to create stable ingestion. The first, batch, relies on grouping and transporting data based on specific criteria. This is often the most efficient methodology, requiring the least compute and storage resources. This may seem counter-intuitive, but the benefit of a batch operation is that it can group together related data. This can enable more efficient storage and compression, especially when column store compression is utilized. In addition, big data systems suffer performance issues when working with lots of small files. A batch operation can combine large numbers of small files together, optimizing the process of writing data to storage. It’s worth noting that most near-real time jobs can use batch operations to improve performance. In these cases, the operations trade off some amount of additional latency to reduce the overall processing cost. Batch operations provide a predictable metric for creating stable ingestion. The batch intervals must be less than the processing intervals
The second type of ingestion methodology is streaming. Streaming methodologies can immediately ingest the data, making it available for analysis or processing. Streaming processes the data as it is received. In truth, most systems will create small batches (called a micro-batch) which are processed in short time intervals (milliseconds). The micro-batches will receive the data over a period of time, perform any requested aggregation, and forward the data to an appropriate sink. Having some level of batching generally improves the overall performance.
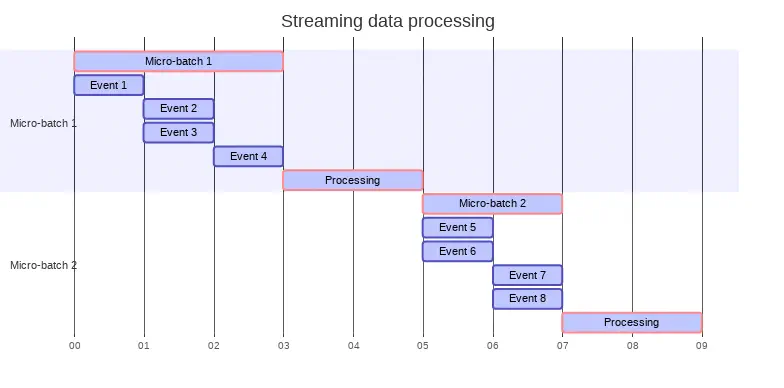
In a continuous processing implementation, the data is processed almost immediately after it is received. This provides lower latency, but can require significantly more compute resources. Implemented improperly, streaming solution of this kind can end up storing a large number of small files. Storing multiple small files is a known anti-pattern with big data storage solutions; these situations can create noticeable performance issues. As a result, continuous processing implementations require additional planning and consideration.
In each case, the ingestion process relies on being able to retrieve data from one of a variety of sources. In Azure, this can include any of numerous services, such as:
- Azure Data Factory (ADF)
- Apache Kafka
- Power Automate
- Spark / Azure Databricks
- Event Grid
- Event Hub
- IoT Hub
- Logic Apps
- Azure Data Explorer
The specific choice of solution to use depends on your ingestion requirements and the source of the data feeds. For example, Azure Data Factory can periodically retrieve batches of data from a remote storage systems. When dealing with large numbers of small devices, Azure IoT Hub can be a a great way to receive the numerous small messages as one part of an ingestion operation. As you learn about each service, you’ll learn about its strengths and limitations. This will help you to understand the best uses for each one.
Once the data has been retrieved from the source system, it’s time to store it somewhere.
But that’s a post for another day. :-)