
A few months ago, I had an interesting question. A team wanted to understand why they were having issues with Checks in GitHub. They created pull requests to merge that branch to multiple others. They want to merge one set of fixes (or enhancements) to branches that represented different product versions. They were wanting something like this:
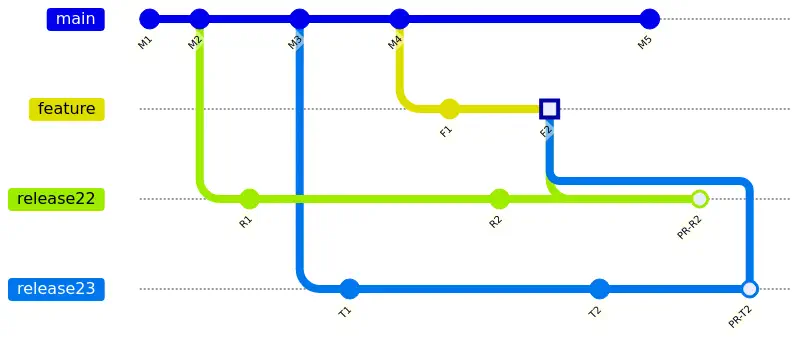
For each merge, they created a pull request. This triggered a build, and each branch ran a set of Checks and validations. When a Check ran, they were surprised to see its results would affect the other branches. For example, release22 branch would finish and show success. If release23 then ran the same Checks and failed the validation, both branches would change to a failing state. As you can imagine, they found the behavior very unexpected!
Why does it happen?
The root cause of this comes from the nature of how Checks work in GitHub. In
Creating GitHub Checks, we learned how Checks execute. GitHub essentially stores needs three values: the SHA for the commit, the name for the Check, and the results. When a PR is created, it associates a source branch. The PR then uses the latest commit on that branch for Actions workflows and any related Checks. In this case, the merge pattern the teams were using resulted in each PR tracking the same branch and HEAD commit.
Notice in the diagram that commit F2 is being used for two different PRs (one for release22 and one for release23) Both PRs have the same source branch and the same latest commit. Since the commit is the same, Checks from both branches will update their Status against the same SHA. Consequently, all of the PRs are now sharing Check and Status results, and a given Check will always show the latest applied result. For example, let’s assume both branches run a Check called CanMerge. As both PRs run their Checks, the Status will change as shown in this animation:
Naturally, most teams want to know why doesn’t GitHub just update the Check results using the PR? The current design for the Checks API treats them as commit-level changes. This makes sense if you think about it – it needs to be able to annotate the code, and the code only exists as a commit in the branch being merged. This leads to the next question – why not use the PR’s SHA for the Checks?
That’s actually a complicated issue, because there are three SHAs to consider:
- When the PR is created (or the branch is updated), a test commit is created to determine whether there’s a conflict with the target branch. This commit is discarded after the test.
- When a workflow runs in response to a
pull_requesttrigger, GitHub merges the code to the latest version of the target branch and uses this merge for the workflow process. The commit is discarded after the workflow run. - Then the PR is merged to the target branch, the code is merged with the most recent version of that branch. The merge commit is preserved, but this isn’t available until after the PR completes.
As you can see, during a PR there’s no long-lived commit other than the one from the branch being merged. I cover this topic in depth in The Many SHAs of a GitHub Pull Request. This commit at the head of the branch represents the current code, so it’s the optimal place for both Checks and annotations … unless you’re trying to reuse a commit.
The simplicity of the PR/merge process on GitHub is both a strength and weakness. It’s hiding a lot of details, including the various steps and their SHAs. There is a basic rule with Git: you must always pull and merge the latest changes before you can push. The PR/merge process is hiding several different pulls and merges as part of the process. This makes it easier for developers if they are following the generally recommended practices. It also adds unexpected challenges with alternative processes.
As a result, I don’t usually advocate for complex branching schemes such as the one we’re discussing. These approaches often create more work for teams. They also frequently lead to branch drift: one or more branches become so different that it can no longer safely merge with other branches.
At the same time, I recognize that some businesses have strict guidelines that can prevent them from modernizing their branching strategy. They have to make things work – at least for a time – even if it’s not a best practice. To avoid unplanned work impacts, they need a way to make their branch strategy work.
What’s the solution?
To make this approach work, we have to handle part of the process manually. Falling back to classic Git techniques, we need to have a branch that contains each unique merge outcome. There are three steps:
- Create a new branch from each target (
releases22,release23). - Merge the code from the feature branch (
feature) to each new branch, resolving any conflicts. - Create the PR, merging each new branch to its target.
By manually creating a branch for the merge process, we get a few benefits:
- Updates can be applied to the original feature branch, then merged to each of the individual feature-merge branches.
- Changes required for integrating the code to a target branch can be managed using an isolated commit/branch. Changes won’t affect the other branches. Every time I’ve seen teams with this pattern, they already create a new branch if there’s a merge conflict or runtime issue. This avoids the modified code being applied to the other branches.
- The branches we’ve created will have their own SHA for the merged code.
- The creation of these branches can be automated, if required.
- The branches are independently testable and correctable. Sometimes code requires branch-specific changes, especially when the branch represents a legacy version.
The tradeoff? Comments on one targeted branch of the code will not automatically apply to all of the branches, and changes on the downstream branches may not be readily mergeable back to the original feature branch.
The modified flow looks like this:
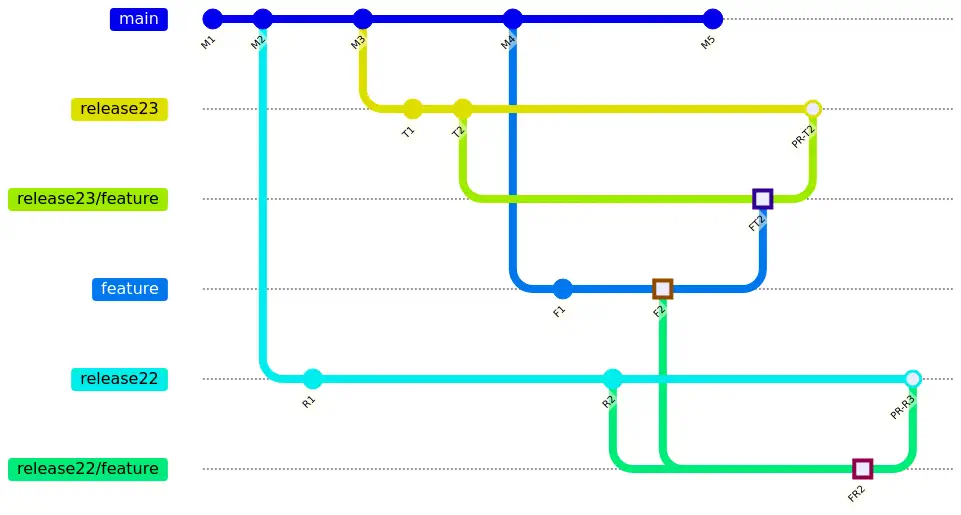
For the example above, start by creating a branch from release22 called release22/feature and checkout that branch. Next, merge feature to release22/feature. The branch release22/feature now represents the proposed merge results and has its own unique commit SHA. Finally, create a PR from release22/feature to release22.
Repeat this process for release23, creating a branch specifically for the merge. The results of the Checks are now separate for both of the PRs. Notice that instead of F2 being the commit for each merge, we are instead merging FT2 and FR2. Because these are different commits (and different SHAs), we see the expected behavior. As the PRs are completed, its feature-merge branch can be deleted. When all of the feature-merge branches have been removed, the original feature branch can be deleted.
This approach also works if you create two branches from feature (i.e., feature-release22, feature-release23), then merge the respective release branches into its associated integration branch. From there, merge each integration branches to its related releaseXX target branch.